Unlock the power of scalable machine learning pipelines with AWS! In this in-depth guide, we explore how to build efficient end-to-end ML workflows using AWS’s suite of tools, whether you're working in e-commerce, healthcare, or finance, this article provides real-world use cases and practical insights to help you design ML solutions that are flexible, cost-effective, and future-proof.

On this page
Data Ingestion and ETL with AWS
Model Development and Training with AWS
Model Evaluation and Iteration
Model Deployment and Monitoring
Conclusion
When developing software for third parties, it’s important to avoid delivering intricate, black-box style solutions that are as beautiful as they are fragile. For many of our clients at Valere, a modular, cloud-based solution for ML development is just as important as something that delivers a precise answer but that can’t be maintained, modified, or updated. Leveraging AWS’s comprehensive tooling for all phases of ML development - from data ingestion, to storage, to model development and monitoring - is a key component of our success as an agency. Come say hi at the AWS re:Invent conference next week - we’d love to talk to you about what we’ve built and how our solutions work for you.
As the world of machine learning (ML) continues to evolve, building scalable, efficient, and robust ML pipelines has become critical for organizations aiming to leverage the power of data. AWS provides a suite of powerful, hosted services that streamline the process of creating end-to-end ML pipelines, from data ingestion and preprocessing (ETL) to model development, deployment, and iteration. With these services, businesses can easily scale their operations and ensure that their ML models remain optimized and deliver real-time, actionable insights.
Let’s explore building a scalable ML pipeline on AWS by leveraging the right tools for each step of the process, including practical use cases from industries like e-commerce and healthcare. We’ll also cover the specific AWS services that can be used to address common challenges faced during the ML lifecycle.
The basic flows look something like:
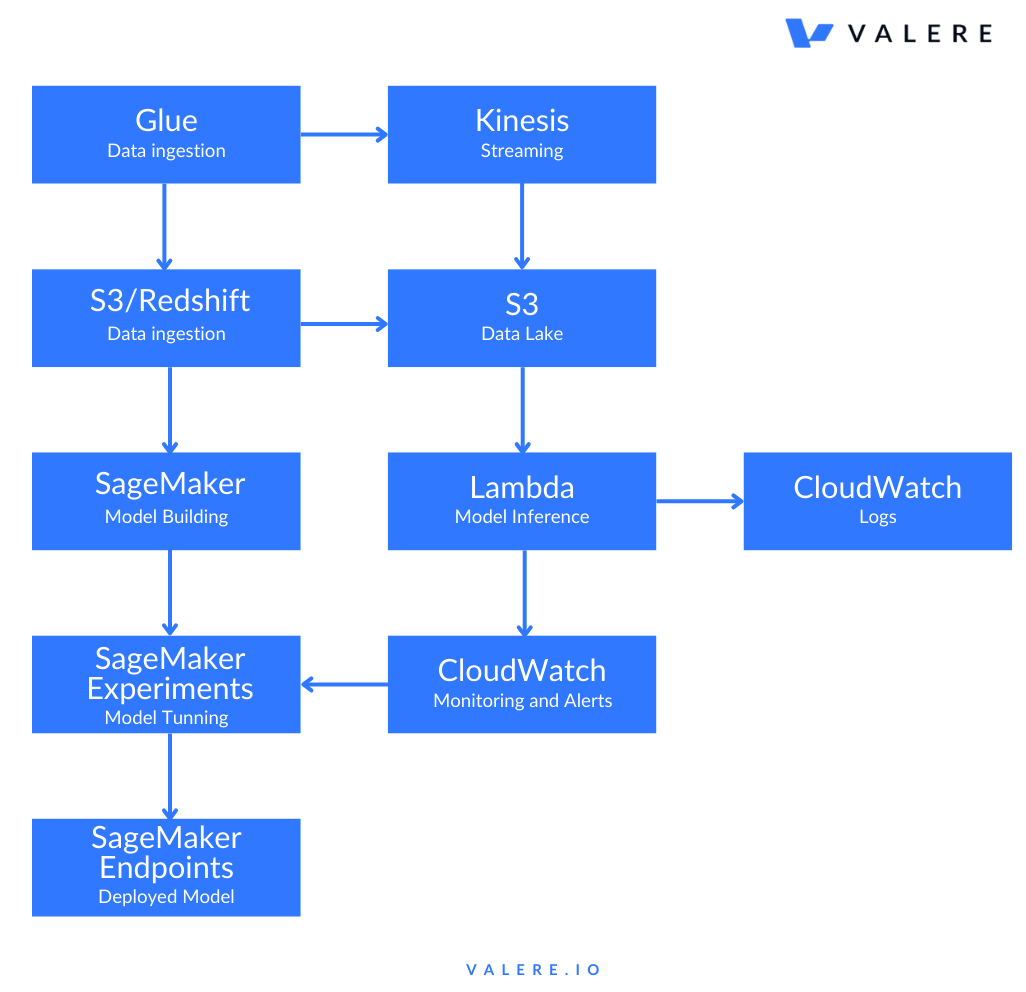
The first step in any ML pipeline is data ingestion and preprocessing (ETL: Extract, Transform, Load). For an ML model to perform well, it needs clean, high-quality data. AWS offers a variety of services to handle data collection, storage, and transformation efficiently.
AWS Glue is a fully managed ETL service that simplifies the process of preparing data for machine learning. Glue allows users to create and run ETL jobs that automatically discover, catalog, clean, and transform raw data from different sources into a format suitable for ML models.
For industries like e-commerce or finance, where real-time data plays a crucial role, AWS Kinesis provides a set of services to ingest and process streaming data. This is essential for building pipelines that respond to real-time events, such as customer activity on a website or transactions.
Once your data is ingested and prepared, the next step is building and training machine learning models. AWS provides several solutions to accelerate model development and training, especially at scale.
Amazon SageMaker is the cornerstone of AWS’s ML offerings. It’s a fully managed service that enables data scientists and developers to build, train, and deploy machine learning models at scale. SageMaker abstracts much of the complexity involved in model development, allowing teams to focus on creating high-quality models.
How it Works:
SageMaker provides multiple tools for every stage of model development:
Model Debugging and Profiling: SageMaker Debugger and Profiler provide in-depth insights into model training, allowing you to identify bottlenecks and ensure that models are training efficiently.
Once models are trained, you need a way to deploy them for inference (i.e., to make predictions in production). AWS Lambda can be used for serverless inference, where models are invoked in response to real-time events or requests.
Once you have models deployed in production, it's crucial to evaluate their performance, fine-tune them, and ensure they continue to deliver optimal results as new data comes in. AWS offers several tools to manage model iteration and performance evaluation.
Model Monitor enables you to automatically track the quality of your machine learning models after deployment. It detects concept drift, where the underlying data distribution changes over time, potentially affecting model accuracy.
When working with multiple models or iterations, Amazon SageMaker Experiments helps you manage and track different versions of models, hyperparameters, and datasets.
After model development, training, and evaluation, deployment is the final step. AWS provides fully managed services for deploying models into production and monitoring their performance.
SageMaker Endpoints allow you to deploy machine learning models for real-time inference at scale. This is ideal for applications where latency is crucial, such as personalized recommendations or fraud detection.
To monitor your deployed ML models, AWS CloudWatch integrates seamlessly with SageMaker to track metrics such as latency, request volume, and model performance.
Building scalable, efficient machine learning pipelines on AWS is a powerful way to leverage data for real-time insights and decision-making. From data ingestion with AWS Glue and Kinesis to model development and deployment with SageMaker, AWS provides a complete, managed ecosystem for end-to-end ML pipelines. The scalability, automation, and flexibility of AWS tools ensure that ML models can handle large, dynamic datasets, making them ideal for industries like e-commerce, healthcare, and finance.
By combining AWS’s managed services, organizations can focus on building and iterating on their machine learning models rather than worrying about infrastructure management. The result is a highly efficient, cost-effective pipeline that continuously improves as data evolves and models are iterated, delivering value at scale. Our Discovery process at Valere helps us help you determine how far into the weeds you’d like to go, allowing us to deliver a product that will both fit your short-term use case and evolve over time, growing with the complexity of your business with minimal investment of time and money.
If you want to apply this knowledge in real-world AI projects, listen to our podcast #1: Unlocking AI's Potential From Theory to Practice. This episode explores AI/ML implementation, practical applications, and assessing AI solutions, helping you with actionable insights.
Share