Retrieval Augmented Generation (RAG): Ultimate Guide

By: Valere Team
Table of contents:
Introduction to Retrieval Augmented Generation (RAG)
Why is called RAG?
The History of Retrieval Augmented Generation (RAG)
Who Invented Retrieval Augmented Generation?
What is Retrieval Augmented Generation?
Why You Need to Know About Retrieval Augmented Generation?
How Does Retrieval Augmented Generation Works?
How to Implement Retrieval Augmented Generation
RAG Components
Retrieval Augmented Generation Tutorial
RAG Architecture
RAG Frameworks
Retrieval Augmented Generation example and ideas
RAG Use Cases and Ideas of How To Use RAG
Data Governance and Data Readiness for RAG
Benefits of Retrieval-Augmented Generation
How to evaluate Retrieval Augmented Generation?
Conclusion
Introduction to Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combines the strengths of traditional information retrieval systems (such as databases) with the capabilities of generative large language models (LLMs). By integrating external knowledge with its skills, the AI can produce answers that are more accurate, up-to-date, and relevant to specific needs. If you want to understand the basics of RAG take a look at this article.
Why is called RAG?
Patrick Lewis, the primary author of the paper that first presented RAG in 2020, named the acronym that currently characterizes an expanding array of techniques utilized in countless papers and multiple commercial services. He believes these represent the forthcoming evolution of generative AI.
Patrick Lewis leads a team at AI startup Cohere. He talked about how they came up with the name in an interview in Singapore where he shared his ideas with a conference of database developers in the region:
“We always planned to have a nicer sounding name, but when it came time to write the paper, no one had a better idea.” Lewis said.
Check out this interview of Lewis about RAG:
https://www.youtube.com/watch?v=Dm5sfALoL1Y
The History of Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a technique that combines the strengths of information retrieval and natural language generation to produce highly relevant and accurate responses to user queries. The roots of RAG trace back to the early 1970s, a period marked by the pioneering efforts in developing question-answering systems.
The Early Beginnings: 1970s
In the 1970s, researchers began exploring information retrieval and natural language processing (NLP) to develop systems that could answer questions posed in natural language. These early question-answering systems were rudimentary and focused on narrow domains, such as baseball statistics. Despite their limited scope, these systems laid the foundational concepts for future advancements in text mining and information retrieval. We highly recommend the movie Moneyball to see a clear example of using statistics for prediction in sports.
Steady Progress: 1980s and 1990s
A notable milestone during this era was the launch of Ask Jeeves in the mid-1990s. This service, now known as Ask.com, popularized question-answering by allowing users to ask questions in natural language. After this, many other platforms created alternatives like search engines (google, yahoo) and question-based sites like Reddit and Quora.
Breakthroughs in the New Millennium: 2000s and 2010s
The early 2000s and 2010s witnessed groundbreaking advancements in question-answering systems. In 2011, IBM's Watson gained fame for defeating two human champions on the TV show Jeopardy!. This was a significant accomplishment. Watson's success demonstrated the potential of combining information retrieval with advanced NLP and machine learning techniques.
So Who Invented Retrieval Augmented Generation?
Since its publication, hundreds of papers have cited the Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks paper, building upon and expanding its concepts to make it a significant contribution to ongoing research in this field.
In 2020, the paper was published while Lewis was pursuing his doctorate in NLP at University College London and working for Meta at a new AI lab in London. The team aimed to enhance the knowledge capacity of large language models (LLMs) and developed a benchmark to measure their progress.
Drawing inspiration from previous methods and a paper by Google researchers, the team envisioned a trained system with an embedded retrieval index that could learn and generate any desired text output, according to Lewis.
What is Retrieval Augmented Generation?
RAG optimizes the output of a large language model by referencing an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences.
RAG extends the capabilities of LLMs to specific domains or an organization's internal knowledge base without needing to retrain the model. This cost-effective approach ensures that LLM outputs remain relevant, accurate, and useful in various contexts.
Incorporating RAG into enterprise search provides cost-saving benefits by automating complex search processes, reducing manual effort, and optimizing resource allocation. This leads to financial savings and improved operational efficiency for organizations.
RAG’s role is not just about improving search results. It also helps with informed decision-making and strong business intelligence. By using insights from extensive data sets powered by RAG, businesses can see their operations more clearly. This understanding helps leaders make informed, data-driven decisions, encouraging agility and adaptability in a constantly changing business environment.
Successful cases demonstrate how RAG significantly improves search relevance, increases productivity, and reduces costs. Measurable indicators of ROI from RAG implementation include enhanced search accuracy, reduced search time, and lower operational expenses.
Case Study: For one of the largest equipment rental companies, Valere created an AI agent-based solution that addresses over two million minutes in annual call time.
Why You Need to Know About Retrieval Augmented Generation?
It promises to drastically enhance the usability of LLMs. LLMs are powerful tools, but their integration into applications can be challenging due to issues with accuracy and transparency. RAG addresses these problems by connecting an LLM to a data store, ensuring that responses are both accurate and verifiable. it can be used by nearly any LLM to connect with practically any external resource.
Neural networks known as Large Language Models (LLMs) are frequently assessed based on their number of parameters. These parameters encapsulate broad patterns of language use, enabling LLMs to construct coherent sentences.
This encoded understanding, termed parameterized knowledge, allows LLMs to generate rapid responses to general queries. However, this approach has limitations when users require in-depth information on specialized or up-to-date subjects.
Problems with Current LLMs
Out-of-Date Information: LLMs often provide answers based on outdated data. For instance, ChatGPT might state it only has knowledge up to September 2021, leading to obsolete or incorrect answers, especially in fields like scientific research.
Lack of Source Transparency: LLMs do not provide sources for their information, requiring users to blindly trust the accuracy of the answers.
Trust: You might not trust LLMs answers on specific topics or tasks, even if you create your own agent.
How RAG Solves These Problems
RAG connects an LLM to a data store, allowing it to retrieve up-to-date information when generating responses. For example, if you want to use an LLM to get current NFL scores, RAG would enable it to query a real-time database of NFL scores and incorporate this information into its response. This approach ensures the accuracy of the information and provides a clear source.
How Does Retrieval Augmented Generation Works?
RAG systems operate in two phases: Retrieval and Content Generation.
Retrieval Phase: Algorithms actively search for and retrieve relevant snippets of information based on the user’s prompt or question using algorithms. This retrieved information forms the basis for generating coherent and contextually relevant responses.
Content Generation Phase: After retrieving the relevant embeddings, a generative language model, such as a transformer-based model like GPT, takes over. It uses the retrieved context to generate natural language responses. The generated text can be further conditioned or fine-tuned based on the retrieved content to ensure it aligns with the context and is contextually accurate. The system may include links or references to the sources it consulted for transparency and verification purposes.
Take a look at how Valere approaches RAG:
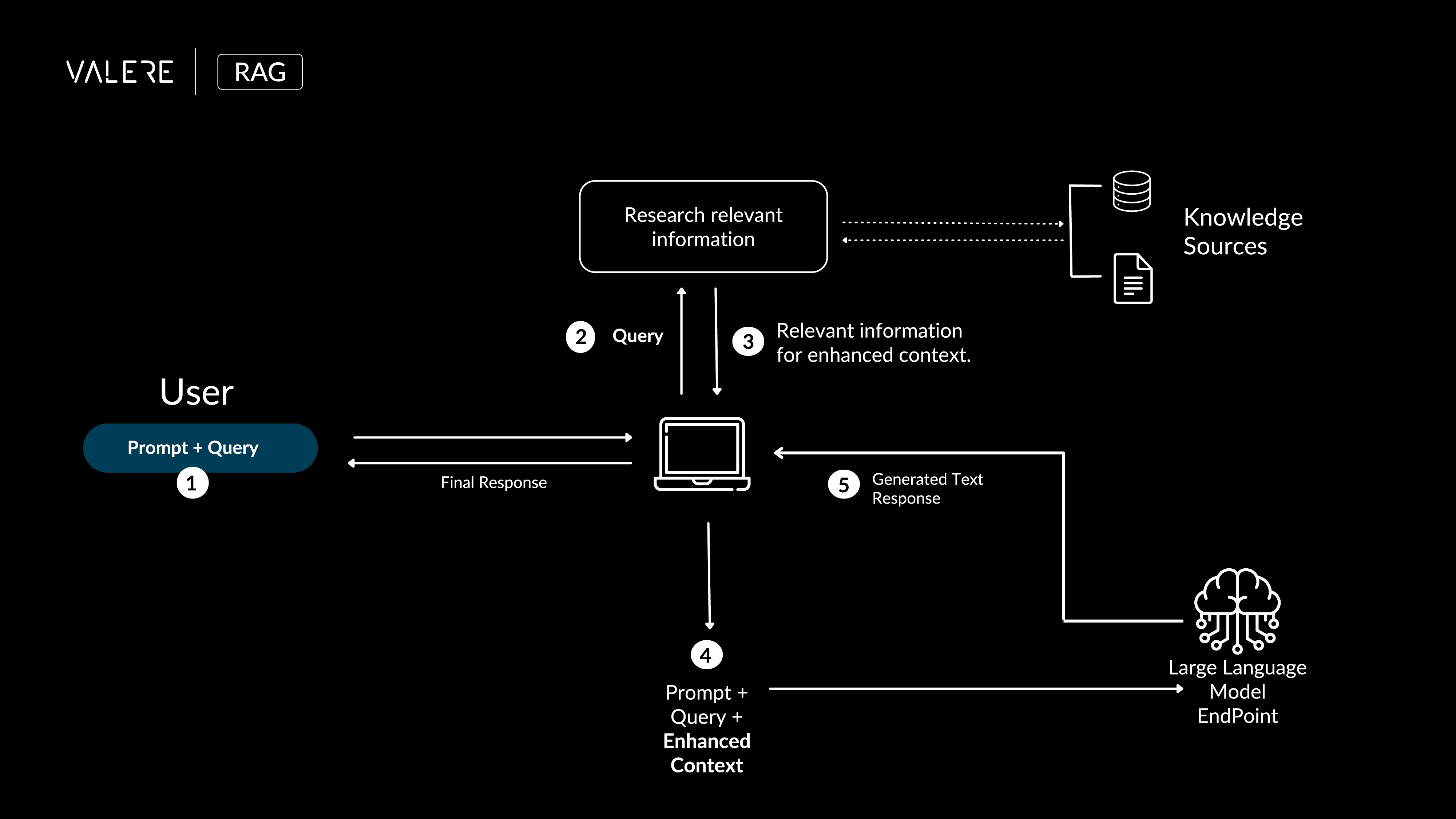
Our process for generating high-quality text responses involves several key steps. First, we receive a prompt and query from the user, which is then sent to our search system to find relevant information from various knowledge sources. This information is combined with the original input to create an enhanced context.
Using this enhanced context, we generate a detailed and accurate response with our large language model. This ensures that our responses are well-informed, precise, and tailored to the user's needs.
And there you have it! The five steps of Retrieval-Augmented Generation: creating external data, retrieving relevant information, augmenting the prompt, updating external data, and generating the response.
How to Implement Retrieval Augmented Generation
Retrieval Engine: The Retrieval Engine is responsible for searching and ranking relevant data based on a query. It scours extensive databases and indexes to find the most pertinent information that can support and enrich the response generated by the system.
Augmentation Engine: The Augmentation Engine takes the top-ranked data from the Retrieval Engine and adds it to the prompt that will be fed into the Language Learning Model (LLM). This step ensures that the LLM has access to the latest and most relevant information.
Generation Engine: The Generation Engine combines the LLM's language skills with the augmented data to create comprehensive and accurate responses. It synthesizes the retrieved information with the pre-existing knowledge of the LLM to deliver precise and contextually relevant answers.
Internal vs. External Data
Internal Data: Internal data consists of extensive text collections, such as books and articles, that LLMs are trained on. This data forms the foundational knowledge base for the LLM, providing a broad spectrum of information.
External Data: External data includes real-time information such as recent news, latest research, and specific organizational data. RAG leverages this data to enhance responses, ensuring they are up-to-date and relevant to the current context.
RAG Components
Data Indexing: The first step involves organizing external data for easy access. This can be achieved through various indexing strategies that make the retrieval process efficient.
Different strategies include:
Search Indexing: Matches exact words.
Vector Indexing: Uses semantic meaning vectors.
Hybrid Indexing: Combines search and vector indexing methods for comprehensive results.
Input Query Processing: This step fine-tunes user queries to ensure they are compatible with the search mechanisms. Effective query processing is crucial for accurate and relevant search results.
Search and Ranking: In this phase, the system finds and ranks relevant data using advanced algorithms. These algorithms assess the relevance of data to ensure the most pertinent information is retrieved.
Prompt Augmentation: Here, the retrieved top-ranked data is incorporated into the original query. This augmentation provides the LLM with additional context, making the responses more informed and accurate.
Response Generation: Finally, the LLM uses the augmented prompt to generate a response. This response combines the LLM's inherent knowledge with the newly retrieved external data, ensuring accuracy and relevance.
Retrieval Augmented Generation Tutorial
If you want to learn more, take a look at this five-minute class about Retrieval Augmented Generation we created:
Step 1: Prompt
First, the bot receives a prompt and query from the user, which is then sent to the search system to find relevant information from various knowledge sources.
Step 2: Input Query Processing
Input query processing refines user queries to improve search compatibility. It employs methods tailored to the type of indexing used (search, vector, hybrid) to enhance the search process's effectiveness.
Step 3: Search
The search step involves reviewing the indexed data and ranking results based on relevance. It uses various algorithms such as:
TF-IDF
BM25
Word Embeddings
Cosine Similarity
Deep Learning Models
Step 4: Prompt Augmentation
Prompt augmentation incorporates the top-ranked data into the original query, providing the LLM with the necessary context to generate well-informed and up-to-date responses.
Step 5: Response Generation
In the final step, the LLM generates a response using the augmented prompt. This response integrates the LLM's pre-existing knowledge with the newly retrieved external data, ensuring it is both accurate and relevant.
RAG Architecture
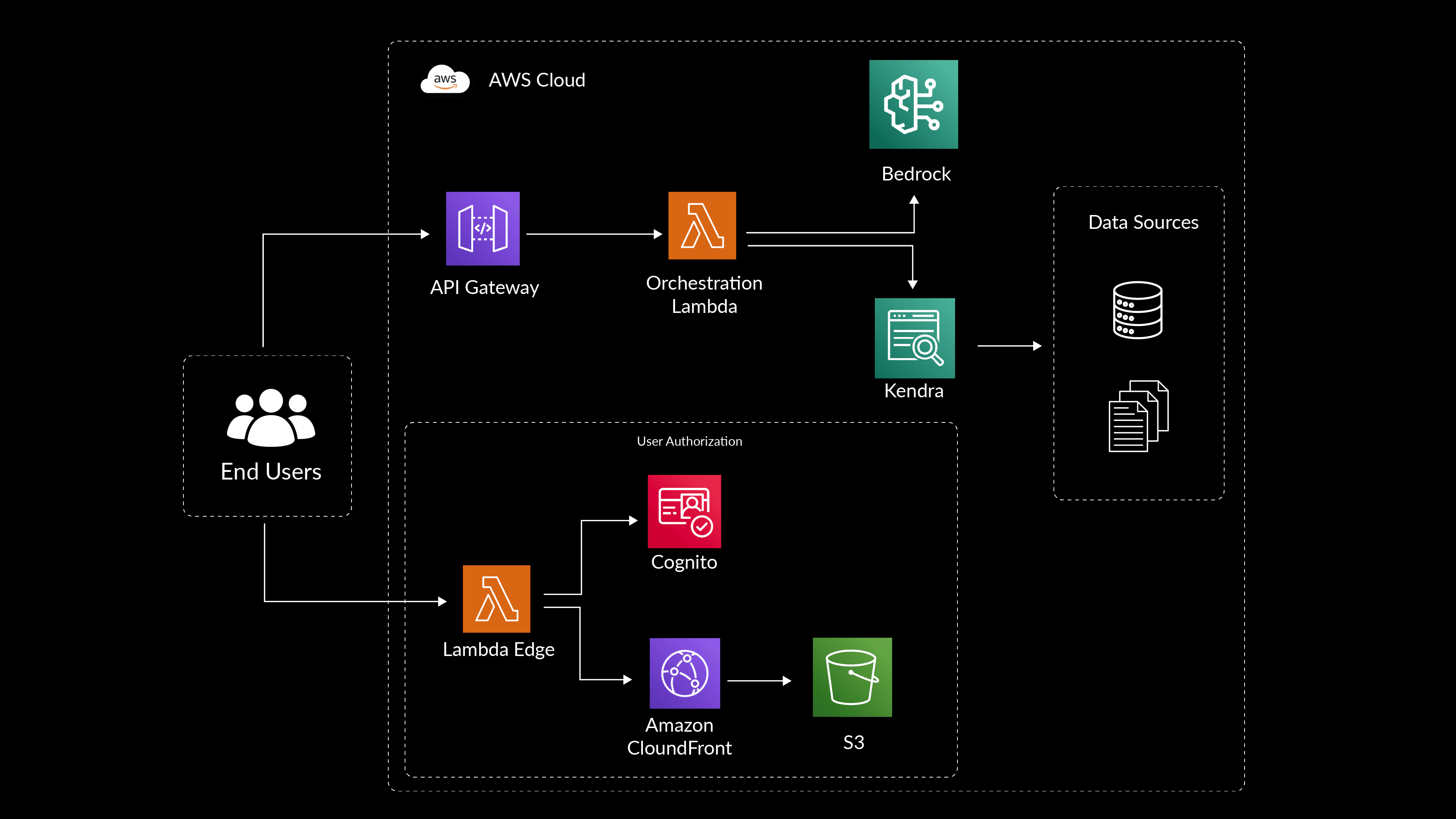
Here is an example of a RAG architecture we have leverage for an RAG process:
At a minimum, a solution of this type needs user authorization, a database, a large language model, data indexing, source control, a storage service, and a hosting server.
Vectorized Databases
Vectorized databases are a cornerstone of RAG. They store data as vectors, enabling efficient similarity searches. These databases facilitate rapid retrieval of relevant information, which can then be used by the LLM to generate contextually accurate responses.
The use of vectorized databases ensures that the information retrieved is both relevant and up-to-date, enhancing the overall performance of RAG systems. Pinecone and Faiss are prominent vector databases utilized in RAG implementations, allowing for scalable and efficient retrieval processes.
Embeddings
Embeddings convert data into a numerical format that LLMs can process. They represent words, sentences, or even entire documents as dense vectors in a high-dimensional space.
Index
Indexes organize these embeddings to enable quick retrieval of information. Proper indexing is crucial for the efficient functioning of RAG, as it ensures that the most relevant data can be accessed swiftly.
Google's BERT model uses embeddings to improve search relevance and similar techniques are applied in RAG to enhance response accuracy.
RAG Frameworks
Integration frameworks (e.g., LangChain and Dust) simplify the development of context-aware and reasoning-enabled applications powered by language models. These frameworks provide modular components and pre-configured chains to meet specific application requirements while customizing models. Users can combine these frameworks with vector databases to employ RAG in their LLMs.
Langchain
LangChain has emerged as a game-changing tool for developers working with large language models (LLMs). Launched in October 2022 by Harrison Chase, this open-source orchestration framework quickly became the fastest-growing project on GitHub by June 2023, showcasing its immense popularity and utility in the AI community.
So, does Langchain use retrieval augmented generation?
Conversely, LangChain's primary appeal lies in its ability to streamline the development of LLM-based applications. Providing a centralized environment and a generic interface for various LLMs, allows developers to mix and match different models and components with ease. This flexibility is crucial in a field where new models and techniques emerge constantly.
At its core, LangChain consists of several key components. The LLM module serves as a universal adapter for different language models, while the Prompts feature offers templated instructions for guiding LLM responses. Chains, the framework's namesake, enable the creation of complex workflows by linking multiple components.
For data integration, LangChain provides Indexes to access external sources, including document loaders and vector databases. The framework also addresses the challenge of maintaining context in conversations through its Memory utilities and incorporates Agents that can use LLMs for autonomous decision-making and action.
LangChain's versatility has led to its adoption in various applications. From sophisticated chatbots and text summarization tools to question-answering systems and data augmentation for machine learning, the framework has proven its worth across diverse use cases.
Perhaps most intriguingly, LangChain's agent modules open up possibilities for creating virtual agents capable of complex task automation.
As AI continues to reshape industries, LangChain stands out as a vital tool for developers looking to harness the power of large language models. Its open-source nature, coupled with related tools like LangServ and LangSmith, ensures that it remains at the forefront of AI application development.
By simplifying the integration of LLMs into various workflows and reducing the complexity of building AI-powered systems, LangChain is not just riding the wave of AI innovation – it's helping to drive it forward.
Llama Index
LlamaIndex has emerged as a formidable player, offering a unique blend of simplicity, flexibility, and power. While it may not have been mentioned much, LlamaIndex deserves recognition as a valuable tool for developers and organizations looking to implement RAG systems.
Simplifying Data Ingestion and Structuring
One of LlamaIndex's standout features is its ability to simplify the process of ingesting and structuring data from various sources. Whether you're working with PDFs, web pages, APIs, or databases, LlamaIndex provides intuitive tools to transform raw data into queryable knowledge bases. This ease of use significantly reduces the time and effort required to prepare data for RAG applications.
Flexible Query Interfaces
LlamaIndex shines in its approach to querying data. It offers multiple query interfaces, including natural language, structured, and hybrid approaches. This flexibility allows developers to choose the most appropriate method for their specific use case, whether it's a conversational AI application or a more traditional search system.
Optimized for Large Language Models
While LlamaIndex is model-agnostic, it's particularly well-optimized for working with large language models (LLMs). It provides seamless integration with popular LLMs and offers tools to manage context length, an important consideration when working with models that have fixed input size limits.
Advanced RAG Techniques
LlamaIndex doesn't just stop at basic RAG functionality. It incorporates advanced techniques such as multi-step reasoning, query transformations, and dynamic prompt construction. These features enable developers to build more sophisticated and context-aware AI applications.
Scalability and Performance
As applications grow, so do their data needs. LlamaIndex addresses this with support for vector stores and databases, allowing for efficient storage and retrieval of large-scale embeddings. It also offers caching mechanisms to improve performance in production environments.
Active Development and Community Support
One of LlamaIndex's strengths is its active development and engaged community. Regular updates introduce new features and improvements, while a growing ecosystem of tutorials, examples, and third-party integrations makes it easier for developers to get started and extend the framework's capabilities.
Emphasis on Evaluation and Debugging
Building effective RAG systems requires careful tuning and evaluation. LlamaIndex provides built-in tools for evaluating query results, analyzing retrieval performance, and debugging RAG pipelines. These features are invaluable for iterating on and improving RAG applications.
Interoperability with Other Tools
LlamaIndex doesn't try to reinvent the wheel. Instead, it offers easy integration with other popular tools in the AI ecosystem. This includes compatibility with frameworks like LangChain, making it possible to leverage the strengths of multiple libraries in a single project.
Focus on Explainability
In an era where AI transparency is increasingly important, LlamaIndex's focus on explainability is noteworthy. It provides tools to trace how information flows through the RAG pipeline, helping developers understand and explain the system's outputs.
LlamaIndex has carved out a significant niche in the RAG framework landscape by offering a compelling mix of user-friendliness and advanced features. Its ability to simplify complex RAG workflows while still providing the flexibility for customization makes it an attractive option for both newcomers and experienced AI developers.
As the field of RAG continues to evolve, LlamaIndex's active development and growing community suggest that it will remain a key player in shaping the future of AI-powered information retrieval and generation systems. For anyone exploring RAG frameworks, LlamaIndex certainly deserves a spot on the shortlist of tools to consider.
Retrieval augmented generation example: Journalist and Librarian
Imagine you're a journalist wanting to write an article on a specific topic. You have a general idea but need more detailed research.
You go to a library, which has thousands of books on various subjects. How do you find the relevant books?
You ask the librarian. The librarian, an expert on the library's contents, retrieves the relevant books for you. While the librarian isn't the expert on writing the article, and you're not the expert on finding the most up-to-date information, together, you can get the job done.
This process is similar to RAG, where large language models call on vector databases to provide key sources of data and information to answer a question.
In a business context, let's say a business analyst wants to know, "What was revenue in Q1 from customers in the Northeast region?" The LLM can understand "What was our revenue?" but not the specifics of "Q1 from customers in the Northeast."
This specific information changes over time and is unique to the business. Therefore, the LLM queries a vector database, retrieves the relevant data, and incorporates it into the prompt. The LLM then generates an accurate and up-to-date response based on the retrieved data.
RAG Use Cases and Ideas of How To Use RAG
Let’s see this case study we created with one of our RAG Projects:
And we list some ideas on how to use RAG in different industries:
Retail
Use Case: Dynamic Customer Support
Using RAG, retailers can offer dynamic and context-aware customer support, retrieving past interaction history and generating real-time responses to queries.
Travel
Use Case: Customized Itinerary Planning
RAG can generate personalized travel itineraries by retrieving user preferences and past travel data, combining it with current travel trends and options.
Media
Use Case: Content Recommendation
Media platforms can use RAG to enhance content recommendation engines by retrieving user watch history and generating personalized content suggestions.
Finance
Use Case: Fraud Detection and Prevention
RAG can assist in identifying fraudulent transactions by retrieving historical transaction data and generating alerts based on anomalous patterns.
IoT
Use Case: Predictive Maintenance
IoT systems can leverage RAG to predict equipment failures by retrieving historical sensor data and generating maintenance schedules.
Energy
Use Case: Energy Consumption Optimization
RAG can help optimize energy usage by retrieving historical consumption data and generating personalized conservation recommendations.
B2B SaaS
Use Case: Customer Success Management
RAG can enhance customer success strategies by retrieving past usage data and generating tailored recommendations for improving product adoption.
Fitness
Use Case: Personalized Training Programs
Fitness apps can use RAG to create customized workout plans by retrieving user fitness data and generating routines that align with their goals.
Sports
Use Case: Game Strategy and Analysis
RAG can assist sports teams in strategy planning by retrieving historical game data and generating insights on opponent patterns and tactics.
Legal
Use Case: Legal Document Review
Law firms can use RAG to automate the review of legal documents by retrieving relevant case laws and generating summaries or annotations.
Healthcare
Use Case: Personalized Treatment Plans
Healthcare providers can leverage RAG to create personalized treatment plans by retrieving patient medical histories and generating recommendations based on best practices.
Life Sciences
Use Case: Drug Discovery
In life sciences, RAG can aid drug discovery by retrieving relevant scientific literature and generating hypotheses for potential compounds.
Aviation
Use Case: Flight Route Optimization
Airlines can use RAG to optimize flight routes by retrieving historical flight data and generating optimal paths considering current weather and air traffic.
Education
Use Case: Adaptive Learning Systems
Educational platforms can use RAG to create adaptive learning experiences by retrieving student performance data and generating personalized study plans.
Security
Use Case: Threat Detection
Security systems can leverage RAG to detect potential threats by retrieving historical security data and generating real-time alerts.
Real Estate
Use Case: Property Valuation
Real estate firms can use RAG to estimate property values by retrieving historical sales data and generating price predictions based on current market trends.
Marketing
Use Case: Campaign Personalization
Marketing teams can use RAG to personalize campaigns by retrieving customer interaction data and generating targeted marketing messages.
Trucking
Use Case: Route Optimization
Trucking companies can optimize delivery routes using RAG by retrieving historical route data and generating the most efficient paths.
Telecommunications
Use Case: Network Optimization
Telecom companies can use RAG to optimize network performance by retrieving historical usage data and generating recommendations for infrastructure improvements.
Data Governance and Data Readiness for RAG
Data governance encompasses policies, procedures, and standards that ensure data quality, accuracy, and integrity. In RAG systems, high-quality data is essential for both the retrieval and generation phases. Data that is inaccurate or inconsistent can lead to erroneous outputs, undermining the trust and reliability of the AI system. By implementing stringent data governance practices, organizations can maintain high data quality standards, thus enhancing the performance and reliability of RAG applications.
2. Enhancing Data Security and Compliance
With increasing regulatory scrutiny on data privacy and security, organizations must navigate complex legal landscapes to protect sensitive information. Data governance frameworks help in establishing robust security protocols and ensuring compliance with regulations such as GDPR, HIPAA, and CCPA. For RAG systems, which often handle vast amounts of data, this is particularly crucial. Secure and compliant data management practices safeguard against breaches and legal repercussions, enabling the safe deployment of RAG technologies.
3. Facilitating Data Accessibility and Usability
Effective data governance ensures that data is not only secure but also accessible and usable by authorized personnel. This balance is critical in RAG systems, where seamless access to relevant data sources can significantly improve the accuracy and relevance of the generated outputs. Governance frameworks help in defining clear data ownership and access rights, streamlining data retrieval processes and enhancing the overall efficiency of RAG operations.
4. Promoting Transparency and Accountability
Transparency and accountability are cornerstone principles of data governance. By documenting data sources, usage, and transformations, organizations can trace the lineage of data used in RAG systems. This transparency is essential for debugging, auditing, and refining AI models. Accountability mechanisms ensure that data handling practices are aligned with organizational policies and ethical standards, fostering trust among stakeholders.
5. Supporting Scalability and Innovation
As organizations grow and innovate, the volume and variety of data increase exponentially. Data governance provides a structured approach to managing this complexity, supporting scalability and continuous innovation. For RAG systems, which thrive on diverse and extensive datasets, a solid governance framework ensures that data management practices can scale efficiently, enabling the development of more sophisticated and capable AI solutions.
Benefits of Retrieval-Augmented Generation
RAG formulations can be applied to various NLP applications, including chatbots, question-answering systems, and content generation, where correct information retrieval and natural language generation are critical. The key advantages RAG provides include:
Improved Relevance and Accuracy: By incorporating a retrieval component, RAG models can access external knowledge sources, ensuring the generated text is grounded in accurate and up-to-date information. This leads to more contextually relevant and accurate responses, reducing hallucinations in question answering and content generation.
Contextual Coherence: Retrieval-based models provide context for the generation process, making generating coherent and contextually appropriate text easier. This leads to more cohesive and understandable responses, as the generation component can build upon the retrieved information.
Handling Open-Domain Queries: RAG models excel in handling open-domain questions where the required information may not be in the training data. The retrieval component can fetch relevant information from a vast knowledge base, allowing the model to provide answers or generate content on various topics.
Reduced Generation Bias: Incorporating retrieval can help mitigate some inherent biases in purely generative models. By relying on existing information from a diverse range of sources, RAG models can generate less biased and more objective responses.
Efficient Computation: Retrieval-based models can be computationally efficient for tasks where the knowledge base is already available and structured. Instead of generating responses from scratch, they can retrieve and adapt existing information, reducing the computational cost.
Multi-Modal Capabilities: RAG models can be extended to work with multiple modalities, such as text and images. This allows them to generate contextually relevant text to textual and visual content, opening up possibilities for applications in image captioning, content summarization, and more.
Customization and Fine-Tuning: RAG models can be customized for specific domains or use cases. This adaptability makes them suitable for various applications, including domain-specific chatbots, customer support, and information retrieval systems.
Human-AI Collaboration: RAG models can assist humans in information retrieval tasks by quickly summarizing and presenting relevant information from a knowledge base, reducing the time and effort required for manual search.
How to evaluate retrieval augmented generation?
Typically, a foundation model can acquire new knowledge through two primary methods:
Fine-Tuning: This process requires adjusting pre-trained models based on a training set and model weights.
RAG: This method introduces knowledge through model inputs or inserts information into a context window.
Fine-tuning has been a common approach. Yet, it is generally not recommended to enhance factual recall but rather to refine its performance on specialized tasks. Here is a comprehensive comparison between the two approaches:
We recommend using both Fine-Tuning with Retrieval Augmented Generation.
Conclusion
Retrieval-Augmented Generation (RAG) represents a significant advancement in AI, combining the retrieval of relevant information with the generative capabilities of large language models. By leveraging vectorized databases, embeddings, and frameworks like LangChain, RAG systems can deliver accurate and contextually appropriate responses. Effective data governance is crucial to ensuring the reliability and security of these systems.
To explore more about RAG and its applications, consider reading the next references:
- Review detailed use cases and technical insights on IBM's blog: IBM Blog on RAG
- Explore NVIDIA's perspectives on RAG: NVIDIA Blog on RAG
- Understand Google's implementation strategies: Google Cloud RAG Use Cases
- Learn about AWS's approach to RAG: AWS RAG Overview
Other resources to understand and practice with RAG:
- https://arxiv.org/abs/2312.10997
- https://arxiv.org/abs/2210.02627
- https://github.com/infiniflow/ragflow
RAG is poised to revolutionize the way organizations leverage AI, making it an essential area of focus for CIOs, CTOs, and other technology leaders.
Implementing Retrieval-Augmented Generation (RAG) is often an initial milestone in an organization's AI adoption journey. If you're considering RAG implementation but are unsure where to begin, we're here to help. Our experienced team has successfully delivered numerous RAG projects and proofs of concept for a diverse clientele, ranging from startups to Fortune 500 corporations. Let's discuss how we can assist you in taking this important step towards AI integration. Book a consultation here.
